
Claude Opus 4.6 Is Here: Anthropic's Most Capable Model Yet
Anthropic just released Claude Opus 4.6 with a 1M token context window, adaptive thinking, agent teams, and state-of-the-art benchmark results that beat GPT-5.2 and Gemini 3 Pro across the board.
Anthropic just dropped Claude Opus 4.6, and the benchmarks speak for themselves. Released today, February 5, 2026, Opus 4.6 is Anthropic’s most capable model to date—pushing the frontier on coding, reasoning, agentic tasks, and a whole lot more.
Here’s everything you need to know.
The Benchmarks: Opus 4.6 vs. The Competition
Let’s start with the numbers, because they’re significant. Opus 4.6 goes head-to-head with its predecessor Opus 4.5, Sonnet 4.5, Google’s Gemini 3 Pro, and OpenAI’s GPT-5.2 across 15 major evaluations—and leads in the majority of them.
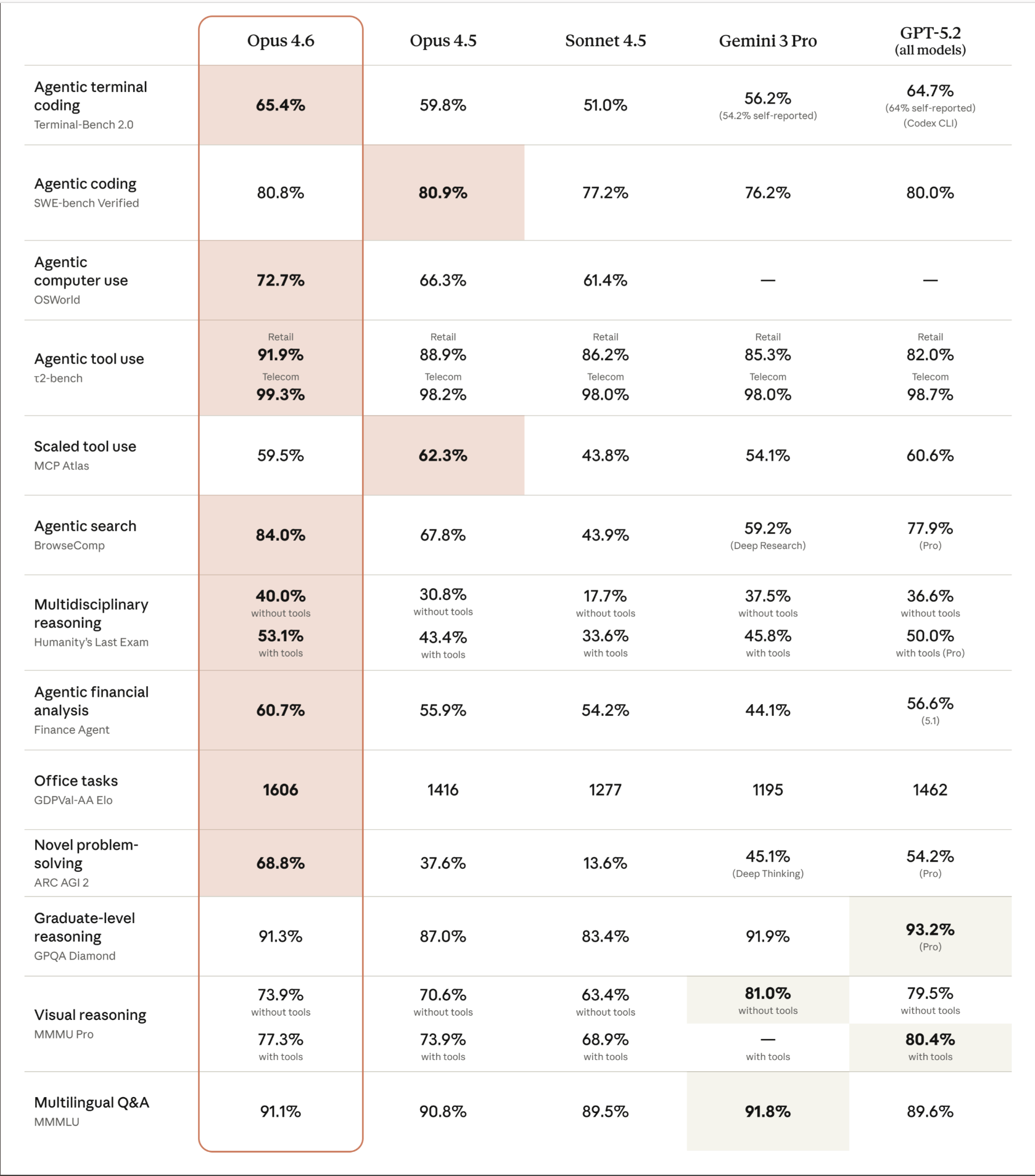
Coding & Agentic Tasks
- Terminal-Bench 2.0 (Agentic terminal coding): Opus 4.6 scores 65.4%, the highest in the industry—beating GPT-5.2’s Codex CLI at 64.7% and leaving Gemini 3 Pro (56.2%) and Opus 4.5 (59.8%) behind.
- SWE-bench Verified (Agentic coding): 80.8%, essentially tied with Opus 4.5’s 80.9% and ahead of GPT-5.2 (80.0%) and Gemini 3 Pro (76.2%).
- OSWorld (Agentic computer use): A commanding 72.7%, a huge jump from Opus 4.5’s 66.3%. Neither Gemini 3 Pro nor GPT-5.2 report scores here.
Tool Use & Search
- τ2-bench (Agentic tool use): 91.9% Retail / 99.3% Telecom—best-in-class across both domains.
- MCP Atlas (Scaled tool use): 62.3% for Opus 4.5 still edges out Opus 4.6’s 59.5% here, but Opus 4.6 beats every other model.
- BrowseComp (Agentic search): A dominant 84.0%, absolutely crushing the competition. GPT-5.2 Pro manages 77.9%, while Opus 4.5 sits at 67.8%.
Reasoning & Knowledge
- Humanity’s Last Exam (Multidisciplinary reasoning): 40.0% without tools, 53.1% with tools—the top score among all frontier models. GPT-5.2 Pro comes close at 50.0% with tools.
- GPQA Diamond (Graduate-level reasoning): 91.3%, competitive with GPT-5.2 Pro’s 93.2% and Gemini 3 Pro’s 91.9%.
- ARC AGI 2 (Novel problem-solving): 68.8%, blowing away the field. GPT-5.2 Pro scores 54.2%, and Gemini 3 Pro Deep Thinking hits 45.1%.
Office & Financial Tasks
- GDPVal-AA (Office tasks): An Elo rating of 1606—outperforming GPT-5.2 by approximately 144 Elo points and its predecessor Opus 4.5 by 190 points. This benchmark measures economically valuable knowledge work, and the gap is massive.
- Finance Agent (Agentic financial analysis): 60.7%, ahead of every competitor.
Multilingual & Visual
- MMMLU (Multilingual Q&A): 91.1%, the highest score, beating Gemini 3 Pro’s 91.8% on this benchmark.
- MMMU Pro (Visual reasoning): 73.9% without tools / 77.3% with tools—competitive across the board, though Gemini 3 Pro leads without-tools at 81.0%.
1 Million Token Context Window
For the first time in an Opus-class model, Claude Opus 4.6 offers a 1 million token context window in beta. That translates to roughly:
- 1,500 pages of text
- 30,000 lines of code
- Over 1 hour of video
This is a game-changer for anyone working with large codebases, lengthy documents, or complex research materials. Previously, the massive context window was only available on lighter models—now the most capable model in Anthropic’s lineup can handle it too.
Adaptive Thinking
Opus 4.6 introduces adaptive thinking, a new approach to reasoning where the model automatically determines when extended thinking is needed based on contextual clues. Instead of manually toggling thinking mode on or off, the model picks up on the complexity of your request and allocates reasoning effort accordingly.
This replaces the previous manual type: "enabled" configuration with budget_tokens. A simpler effort parameter now generally controls thinking depth, making the developer experience much cleaner.
Agent Teams in Claude Code
One of the most exciting features is agent teams in Claude Code. You can now assemble multiple agents to collaborate on complex tasks together. Think of it as having a team of specialized AI coworkers—one handling architecture decisions, another writing tests, another reviewing code—all coordinating on the same project.
This is a direct play against OpenAI’s Codex and signals that Anthropic sees multi-agent collaboration as the future of AI-assisted development.
Compaction API
The new compaction API (in beta) provides server-side context summarization, enabling effectively infinite conversations without hitting token limits. When a conversation gets long, Claude can automatically summarize its own context, compressing earlier parts of the conversation while retaining the important details.
For long-running agentic tasks, this is critical. It means Claude can sustain complex, multi-step workflows without losing track of what happened earlier in the session.
Pricing & Availability
Opus 4.6 is available now across:
- Claude Pro, Max, Team, and Enterprise subscriptions
- Claude API (Developer Platform)
- Amazon Bedrock
- Google Cloud Vertex AI
- Microsoft Foundry
API pricing starts at $5 per million input tokens and $25 per million output tokens, with significant savings available:
- Prompt caching: Up to 90% cost reduction
- Batch processing: 50% discount
This pricing is identical to Opus 4.5, which means you’re getting a significantly more capable model at the same cost.
What This Means for Product Teams
For product managers and product teams, Opus 4.6’s improvements matter in several concrete ways:
Better long-context understanding means AI tools built on Claude can now process entire product backlogs, lengthy PRDs, meeting transcript histories, and complex technical documentation in a single pass—without chunking or losing context.
Improved agentic capabilities mean tools like Telos can execute more complex, multi-step workflows reliably. Think automated ticket creation that considers your full Slack history, codebase architecture, and meeting transcripts simultaneously.
Adaptive thinking makes interactions feel more natural. Simple questions get fast answers. Complex analysis gets the deep reasoning it deserves. No manual configuration needed.
The GDPVal-AA results are particularly telling. This benchmark specifically measures performance on economically valuable knowledge work—the exact type of tasks product managers do every day. Opus 4.6 leads by a wide margin.
The Bigger Picture
The AI model landscape is moving fast. OpenAI’s GPT-5.2, Google’s Gemini 3 Pro, and now Anthropic’s Opus 4.6 are all pushing the frontier in different directions. What stands out about Opus 4.6 is the breadth of its improvements—it’s not just better at coding or reasoning, it’s better at nearly everything, with the notable additions of a massive context window and multi-agent collaboration.
For teams building on top of these models, the message is clear: the capabilities available to AI-powered tools are expanding rapidly, and the gap between what AI can do and what most tools actually leverage is growing wider by the month.